专栏介绍
1.专栏面向零基础或基础较差的机器学习入门的读者朋友,旨在利用实际代码案例和通俗化文字说明,使读者朋友快速上手机器学习及其相关知识体系。
2.专栏内容上包括数据采集、数据读写、数据预处理、分类\回归\聚类算法、可视化等技术。
3.需要强调的是,专栏仅介绍主流、初阶知识,每一技术模块都是AI研究的细分领域,同更多技术有所交叠,此处不进行讨论和分享。
- 数据采集技术:selenium/正则匹配/xpath/beautifulsoup爬虫实例
——————————————————————————————————————————
文章目录
- 专栏介绍
- 概述
- 爬虫思路
- 部分技术的封装案例
- requests+正则获取数据
- requests+xpath获取数据
- request抓包爬取公众号
- 爬虫实战:小白也能看懂的爬虫详细教学
- 1.环境配置
- 2.代码实战
——————————————————————————————————————————
概述
数据采集在机器学习领域中扮演着至关重要的角色。它是数据分析、机器学习和人工智能应用的基础。数据采集的目的是通过各种手段和技术手段,收集、整理、存储和处理各类数据。这些数据可以来自不同的来源,如传感器、日志、社交媒体、数据库等,并可能包括结构化数据、非结构化数据和时序数据等不同类型。
Selenium、正则匹配、XPath和BeautifulSoup是网络爬虫中常用的技术手段,它们各自有不同的特点和用途。
- Selenium:
Selenium是一个自动化测试工具,但它也常被用于网络爬虫中。它允许用户模拟用户的行为,如点击、输入、滚动等,来与网页进行交互。Selenium支持多种浏览器,并通过各种语言的API来控制浏览器行为。它特别适用于JavaScript动态生成的网页内容,因为Selenium可以执行JavaScript,获取网页在完全加载后的状态。 - 正则匹配(Regular Expressions):
正则表达式是一种文本处理工具,它可以用来检查、替换或提取字符串中的特定模式。在爬虫中,正则表达式通常用于从网页的HTML源代码中提取所需信息。它适合于处理结构化或格式化的文本数据,但当HTML结构复杂或变化时,维护正则表达式可能会变得困难。 - XPath:
XPath是一种在XML和HTML文档中查找节点的语言。它通过路径表达式来选取文档中的节点或节点集。XPath在网络爬虫中常用于定位HTML文档中的特定元素,从而提取信息。XPath表达式可以非常精确地定位元素,并且对于大多数静态网页来说非常有效。 - BeautifulSoup:
BeautifulSoup是一个Python库,用于从HTML或XML文件中提取数据。它可以将复杂的HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为四种:Tag、NavigableString、BeautifulSoup和Comment。BeautifulSoup通过解析器来处理HTML文档,并提供了简单的方法和Pythonic语法来访问和修改数据。它特别适合于格式不规范的HTML文档。
此外,还有scrapy框架式爬虫、抓包爬虫等等,数据采集工作的手段丰富多样,此处不一一赘述。
爬虫思路
数据采集工作面向端类众多,如APP、web页面、公众号等等,不同的对象有着不同的爬取思路,当然不同的思路之间也有思想和策略的交叠。
例如:
面向网页端:获取html——信息过滤、筛选——格式化后处理——数据存储
面向app、公众号端:抓包——信息过滤、筛选——格式化后处理——数据存储
…
当然,除此外还有假代理设置、随机ip、cookie伪装、多并发等等应对反爬、提高效率的工作。
部分技术的封装案例
该部分介绍一部分selenium/正则匹配/xpath/beautifulsoup用来爬虫时所用到的模块代码,有基础者可自行取用,无基础或基础较差朋友们经过一定的学习也能看懂,属于比较简单的爬虫模块。
requests+正则获取数据
#导入库
import requests
import jieba
import numpy as np
import pandas as pd
import re
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']='SimHei'#设置中文显示
# http://www.xnwbw.com/html/2021-07/07/node_2.htm
#定义函数
def get_html(target):
html = requests.get(url=target)
html.encoding = html.apparent_encoding#万能解码
return html.text
def get_title(html1):
html = html1
text = re.findall(r'<title>(.*?)</title>',html)
return text
def get_wenzhang(html1):
html = html1
text = re.findall(r'.htm>(.*?)</a> </td></TR> <tr height=27px id=row_black23',html)
return text
def get_picture(html1):
html = html1
#http://www.xnwbw.com/page/1/2021-07/07/A01/20210707A01_brief.jpg
text = re.findall(r'</MAP><img src=../../../(.*?) border=0 USEMAP=#PagePicMap>',html)
return text
#/html/body/div[3]/div[2]/div[2]/ul/li[2]/div[2]/div[2]/div[1]/a/span
link = 'http://www.xnwbw.com/html/2021-07/07/node_2.htm'
html = get_html(link)
title = get_title(html)[0]
wenzhang = get_wenzhang(html)
#print('爬取成功!')
pic_add = tou+get_picture(html)[0]
pic = requests.get(pic_add)
path = 'tupian.png' #获取img的文件名
with open(path, "wb")as f:
f.write(pic.content)
f.close()
部分爬取效果和后处理成果如下:



requests+xpath获取数据
#导入库
import requests
from lxml import etree
import numpy as np
import pandas as pd
import re
#定义函数
def get_html(target,hesders):
html = requests.get(url=target,headers = headers)
html.encoding = html.apparent_encoding#万能解码
return html.text
def get_name(html1):
html = etree.HTML(html1)
text = html.xpath('/html/body/div[5]/div[2]/div[2]/div[1]/div[2]/p/text()')#审查元素,copy,full
return text
#/html/body/div[3]/div[2]/div[2]/ul/li[2]/div[2]/div[2]/a
#模拟浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
#开始爬取
url = 'https://www.17k.com/chapter/3259564/42183056.html'
import urllib.request
from bs4 import BeautifulSoup as bs
def urlopen(url):
req = urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
html = urllib.request.urlopen(req)
html = html.read()
return html
html = urlopen(url)
html = bs(html,'lxml')
content = html.find_all('div',class_="p")
content = content[0].text
print(content)
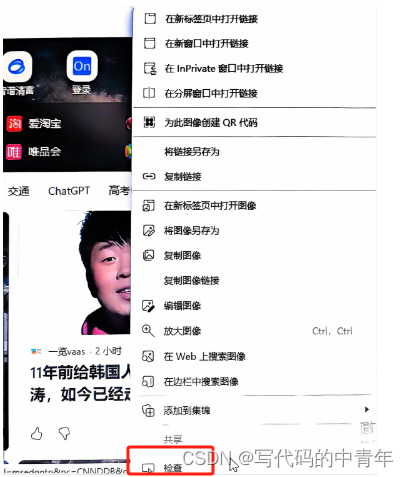
此处强调一下审查元素的操作方法:
text = html.xpath('/html/body/div[5]/div[2]/div[2]/div[1]/div[2]/p/text()')#审查元素,copy,full
其中html字符串可通过选择爬取的元素,右击检查:
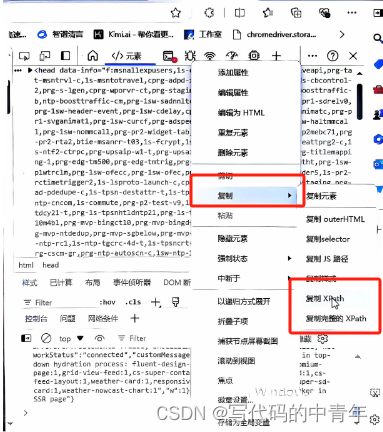
定位到元素代码后对xpath进行提取:
request抓包爬取公众号
# 定义爬虫主函数
def spider(url,headers,config):
# 抓取目标网站的政策名称、政策链接、发布时间、标记
content_list = []
for i in range(2):
print('当前进度:第{}组'.format(str(i+1)))
data["begin"] = i*5
time.sleep(25)
# 使用get方法进行提交
try:
content_json = requests.get(url, headers=headers, params=config).json()
print(content_json)
# 返回了一个json,里面是每一页的数据
for item in content_json["app_msg_list"]:
# 提取每页文章的标题及对应的url
items = []
items.append(item["title"].replace("\"",""))
items.append(item["link"])
# 对政策进行筛选,通不过筛选则不爬取
flags = filter_data(item["title"])
if flags:
items.append(get_date(item["link"]))
items.append(flags)
else:
continue
content_list.append(items)
except:
print('error')
return content_list
# 程序开始运行:
headers = {
"Cookie":"",
"User-Agent": ""
}
token = ""
info1 = pd.read_excel('config.xlsx') # info1中含有token、cookie、User-Agent三项信息
headers["Cookie"] = str(np.array(info1)[0][1])
headers["User-Agent"] = str(np.array(info1)[0][2])
token = str(np.array(info1)[0][0])
info2 = np.array(pd.read_excel('web_list.xlsx')) # info2是主要信息文件,在遍历时起到将配置信息配齐、将爬虫信息配齐以及驱动整个程序的作用
# 0-序列,1-公众号名称,2-url,3-省,4-市,5-区,6-token,7-lang
#8-f,9-ajax,10-action,11-begin,12-count,13-query,14-fakeid,15-type
data = {
"token": "",
"lang": "",
"f": "",
"ajax": "",
"action": "",
"begin": "",
"count": "",
"query": "",
"fakeid": "",
"type": "",
}
result = []
data_0 = datetime.date.today().strftime('%Y%m%d')
sys.stdout = Logger('./log_{}.txt'.format(data_0))
for i in info2:
print('正在爬取:',i[1],i[2])
#对 每个公众号设置一个补全列表,列表内容包括:公众号名称、省、市、区、检索时间
mid_ls = [i[1],i[3],i[4],i[5],str(str2date(time.strftime("%Y-%m-%d %H:%M:%S")))[:10]]
# 每个公众号需要重新配置
data['token'] = str(token)
data['query'] = ''
data['lang'] = str(i[7])
data['f'] = str(i[8])
data['ajax'] = str(i[9])
data['action'] = str(i[10])
data['begin'] = str(i[11])
data['count'] = str(i[12])
data['fakeid'] = str(i[14])
data['type'] = str(i[15])
# 爬
'''
try:
mid_result = spider(i[2],headers,data)
for j in mid_result:# 补
result.append(mid_ls+j)
except:
print('some error.')
'''
mid_result = spider(i[2],headers,data)
for j in mid_result:# 补
result.append(mid_ls+j)
print('爬取完成!')
其中,params的参数获取需要登陆微信公众号后获取cookie等伪装登录信息,具体的内容可以自行在互联网进行搜索解决。再次强调,此处只是分析代码模块片段供有基础的人进行使用,本质上微信公众号爬虫就是抓包获取json数据进行后处理解析。
爬虫实战:小白也能看懂的爬虫详细教学
1.环境配置
网上自行查找anaconda配置教程,之后根据代码所需库进行安装即可,此处强调一下selenium配置教程:
a.下载谷歌浏览器
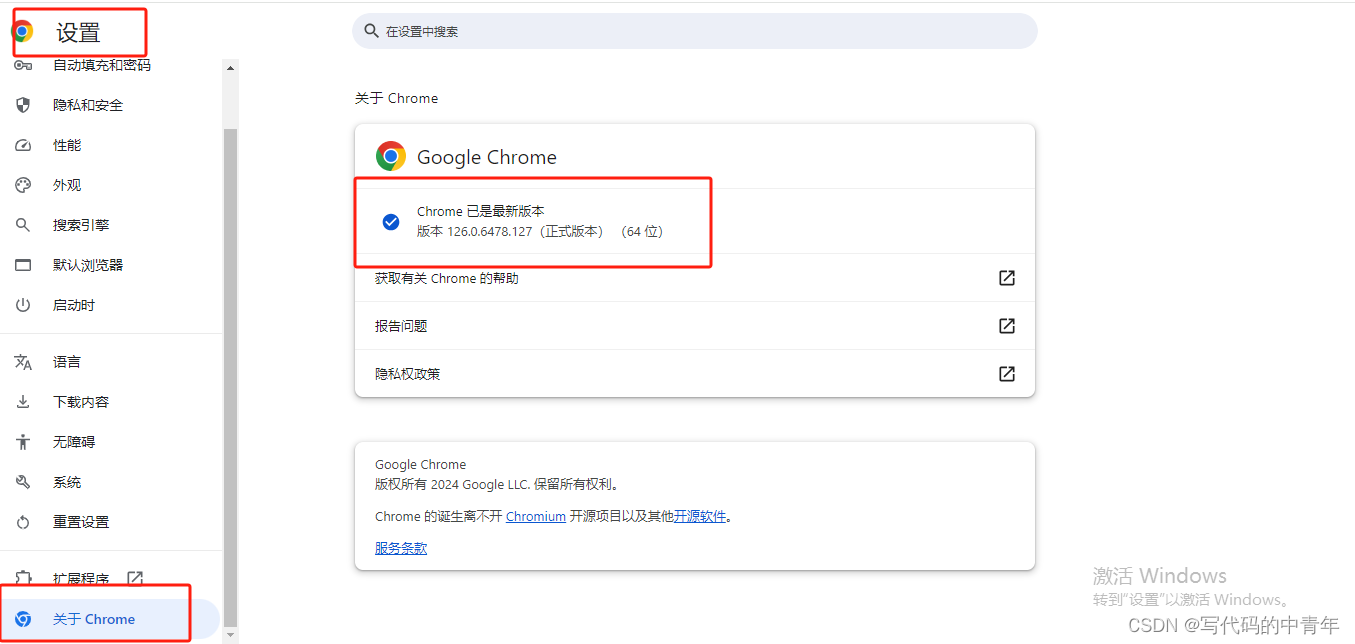
b.设置——关于——查看版本号
c.下载驱动
https://chromedriver.storage.googleapis.com/index.html
https://googlechromelabs.github.io/chrome-for-testing/#canary
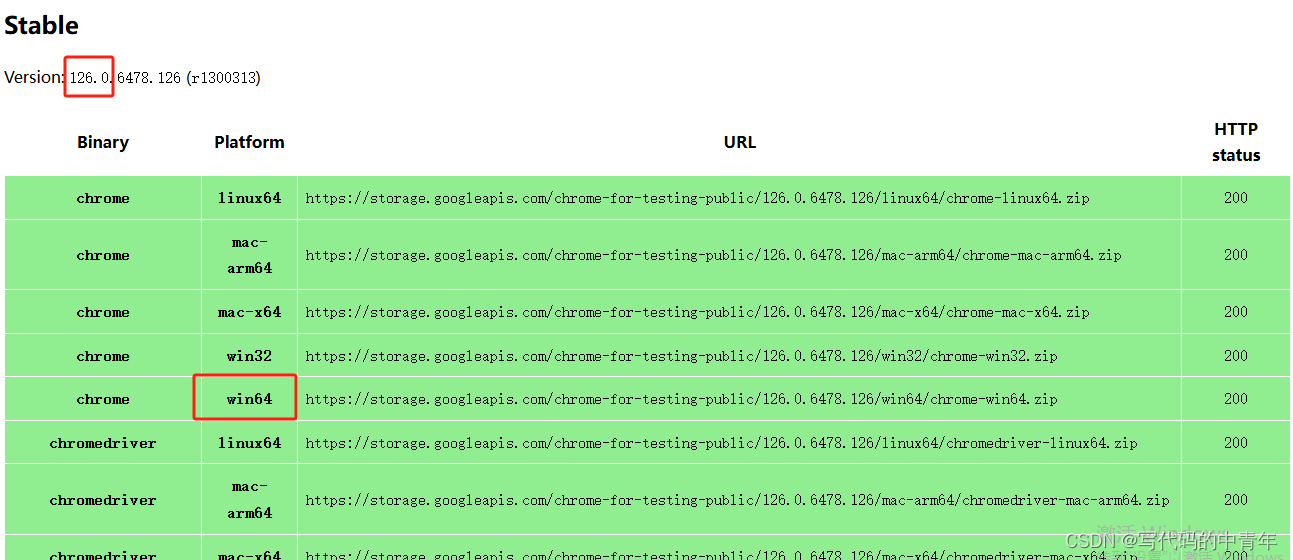
如上图所示,找到最近的版本号(126.0…),选择系统版本通过url链接在浏览器下载即可。
d.打开谷歌浏览器所在位置,将驱动exe程序粘贴即可。

2.代码实战
导入环境
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import requests
from bs4 import BeautifulSoup
创建data.txt文件,内容如下:
利用不可移动文物举办展览、展销、演出等活动的许可
53ca826d-795d-4bdc-b666-ec97a0dd3aa5
机动车驾驶员培训教练场经营备案(新增)
263c2b6a-0d6c-443b-ab1e-bbcc6c01e13b
获取针对一个页面获取一个html:
options = webdriver.ChromeOptions()
# 添加无头模式选项
options.add_argument("--headless")
# 创建一个Chrome浏览器实例
driver = webdriver.Chrome(options=options,
executable_path=r'C:\Program Files\Google\Chrome\Application\chromedriver.exe')
# 打开目标网页
driver.get('http://ytzwfw.sd.gov.cn/yt/icity/proinfo/index?code=53ca826d-795d-4bdc-b666-ec97a0dd3aa5')
html = driver.page_source
打印html观察其有效元素在html中的分布:


根据分布设计数据过滤、采集的代码,主要靠bs4实现:
def get_single_data(name: str, url: str, data) -> dict:
options = webdriver.ChromeOptions()
# 添加无头模式选项
options.add_argument("--headless")
# 创建一个Chrome浏览器实例
driver = webdriver.Chrome(options=options,
executable_path=r'C:\Program Files\Google\Chrome\Application\chromedriver.exe')
# 打开目标网页
driver.get(url)
html = driver.page_source
mid_time = driver.find_element(By.CLASS_NAME, 'law-time').text
driver.quit()
# html = getHTMLText(url)
soup = BeautifulSoup(html, 'html.parser') # 用BeautifulSoup库解析网页
temps_div = soup.find_all('div', attrs={'class': "table-table"})
raw_content_ls = temps_div[0].select('td')
data[name] = {}
data[name]['实施主体'] = raw_content_ls[0].text
data[name]['承办机构'] = raw_content_ls[1].text
data[name]['事项版本'] = raw_content_ls[4].text
data[name]['办理结果名称'] = raw_content_ls[6].text.replace('\n', '').replace('\t', '').replace('\r', '').replace(' ', '')
data[name]['法定办结时限'] = mid_time # get_end_time(url)
data[name]['是否存在运行系统'] = temps_div[0].select('td[width="30%"]')[-1].text
data[name]['咨询渠道'] = collapse_spaces(
temps_div[0].select('td[colspan="3"]')[-3].text.replace('\r', ' ').replace('\t', ' ').replace('\n', ' '))[1:-1]
data[name]['投诉渠道'] = collapse_spaces(
temps_div[0].select('td[colspan="3"]')[-2].text.replace('\r', ' ').replace('\t', ' ').replace('\n', ' '))[1:-1]
data[name]['受理时间、地点'] = collapse_spaces(
temps_div[0].select('td[colspan="3"]')[-1].text.replace('\r', ' ').replace('\u2003', ' ').replace('\n',
' ').replace(
'\t', ' '))[1:-1]
return data
可以看到,本质上就是通过selenium的find_element、bs4的find_all、select等功能对html标签进行层层解析,从而定位到有效信息。

形成批量化爬取的完整代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import requests
from bs4 import BeautifulSoup
def collapse_spaces(s):
while " " in s:
s = s.replace(" ", " ")
return s
def get_single_data(name: str, url: str, data) -> dict:
options = webdriver.ChromeOptions()
# 添加无头模式选项
options.add_argument("--headless")
# 创建一个Chrome浏览器实例
driver = webdriver.Chrome(options=options,
executable_path=r'C:\Program Files\Google\Chrome\Application\chromedriver.exe')
# 打开目标网页
driver.get(url)
html = driver.page_source
mid_time = driver.find_element(By.CLASS_NAME, 'law-time').text
driver.quit()
# html = getHTMLText(url)
soup = BeautifulSoup(html, 'html.parser') # 用BeautifulSoup库解析网页
temps_div = soup.find_all('div', attrs={'class': "table-table"})
raw_content_ls = temps_div[0].select('td')
data[name] = {}
data[name]['实施主体'] = raw_content_ls[0].text
data[name]['承办机构'] = raw_content_ls[1].text
data[name]['事项版本'] = raw_content_ls[4].text
data[name]['办理结果名称'] = raw_content_ls[6].text.replace('\n', '').replace('\t', '').replace('\r', '').replace(' ', '')
data[name]['法定办结时限'] = mid_time # get_end_time(url)
data[name]['是否存在运行系统'] = temps_div[0].select('td[width="30%"]')[-1].text
data[name]['咨询渠道'] = collapse_spaces(
temps_div[0].select('td[colspan="3"]')[-3].text.replace('\r', ' ').replace('\t', ' ').replace('\n', ' '))[1:-1]
data[name]['投诉渠道'] = collapse_spaces(
temps_div[0].select('td[colspan="3"]')[-2].text.replace('\r', ' ').replace('\t', ' ').replace('\n', ' '))[1:-1]
data[name]['受理时间、地点'] = collapse_spaces(
temps_div[0].select('td[colspan="3"]')[-1].text.replace('\r', ' ').replace('\u2003', ' ').replace('\n',
' ').replace(
'\t', ' '))[1:-1]
return data
titles = []
url_ends = []
with open('data.txt','r',encoding='utf-8')as f:
mid = f.readlines()
for i in range(len(mid)):
if i %2 == 0:
titles.append(mid[i].strip('\n'))
else:
url_ends.append(mid[i].strip('\n'))
print(titles[:10])
print(url_ends[:10])
print(len(titles),len(url_ends))
data = {}
# now:1000
start_index = 0
for index in range(len(titles[start_index:])):
print(titles[index])
url = 'http://ytzwfw.sd.gov.cn/yt/icity/proinfo/index?code={url_end}'.format(url_end=url_ends[index])
print(url)
try:
get_single_data(titles[index],url,data)
print(data[titles[index]])
except Exception as e:
print(e)
print('爬取完成!')
import json
# 将字典转换为JSON格式的字符串
json_string = json.dumps(data, ensure_ascii=False)
# 将JSON字符串写入文本文件
with open('my_get_data.txt', 'w', encoding='utf-8') as file:
file.write(json_string)